 A string containing the pathname and filename of the file containing the data.
A string containing the pathname and filename of the file containing the data.
Readsfixed-formatted ASCII data using a format that you specify.
A string containing the pathname and filename of the file containing the data.
The list of variables into which the data is read. Include as many variable names in var_list as you want to be filled with data, up to a maximum of 255. Note that variables of type structure are not supported. An exception to this is the !DT, or date/time, structure. It is possible to transfer date/time data using this routine.
The value returned by DC_READ_FIXED; expected values are:
A long integer that specifies how many characters comprise a single record in the input data file; use only with column-oriented files. If not provided, each line of data in the file is treated as a new record. For more details about when to use the Bytes_Per_Rec keyword, see Example 5.
Column
A flag that signifies filename is a column-organized file. An array of integers indicating the data/time templates that are to be used for interpreting date/time data. Positive numbers refer to date templates; negative numbers refer to time templates. For more details, see Example 6. To see a complete list of date/time templates, see the PV-WAVE Programmer's Guide.
Filters An array of one-character strings that PV-WAVE should check for and filter out as it reads the data. A character found on the keyboard can be typed; a special character not found on the keyboard is specified by ASCII code. For more details, see Example 2.
Format
A string containing the C- or FORTRAN-like format statement that will be used to read the data. The format string must contain at least one format code that transfers data; FORTRAN formats must be enclosed in parentheses. If not provided, a C format of %1f is assumed. An array of strings; if any of these strings are encountered, PV-WAVE skips the entire record and starts reading data from the next line. Any string is allowed, but the following three strings have special meanings:
Miss_Str An array of strings that may be present in the data file to represent missing data. If not provided, PV-WAVE does not check for missing data as it reads the file. For an example showing how to use the Miss_Str keyword, see DC_READ_FREE, Example 3.
Miss_Vals
An array of integer or floating-point values, each of which corresponds to a string in Miss_Str. As PV-WAVE reads the input data file, occurrences of strings that match those in Miss_Str are replaced by the corresponding element of Miss_Vals. Number of records to read. If not provided or if set equal to zero (0), the entire file is read. For more information about records, see Physical Records vs. Logical Records.
Nskip
Number of physical records in the file to skip before data is read. If not provided, or set equal to zero (0), no records are skipped. An array of integers indicating the variables in var_list that can be resized based on the number of records detected in the input data file. Values in Resize should be in the range:
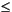 Resizen #_of_vars_in_var_list
Resizen #_of_vars_in_var_list
If neither the Row or Column keywords are provided, the file is assumed to be organized by rows. If both keywords are used, the Row keyword is assumed.
NOTE: This function can be used to read data into date/time structures, but not into any other kind of structures.
The string resource file is:
 wavedir
wavedir /xres/!Lang/kernel/dc.ads
/xres/!Lang/kernel/dc.ads wavedir:[XRES.!Lang.KERNEL]DC.ADS
wavedir\xres\!Lang\kernel\dc.ads
wavedir is the main PV-WAVE directory. The strings that are examined are
DC_binary_check and DC_allow_chars.
DC_binary_check This string can be set to the values True or False. If set to True, the data file is checked for the presence of binary characters before the file is read. If binary characters are found, the file is not read. If this string is set to False, no binary character checking is performed. (Default: True) For example, to turn off binary checking, set the string as follows in the
dc.ads file:
DC_binary_check: False
DC_allow_chars This string lets you specify additional characters to allow in the check for binary files. Before a file is read, the first several lines are checked for the presence of non-printable characters. If non-printable characters are found, the file is considered to be a binary file and the file is not read. By default, all printable characters in the system locale are allowed. Characters may be specified either by entering them directly or numerically by three digit decimal values by preceding them with a "\" (backslash). For example, to allow characters 165 and 220, set the string as follows in the
dc.ads file:
DC_allow_chars: \165\220
As data is being transferred into multi-dimensional variables, those variables are treated as collections of scalar variables, meaning the first subscript of the import variable varies the fastest. For two-dimensional import variables, this implies that the column index varies faster than the row index. In other words, data is transferred into a two-dimensional import variable one row at a time. For more details about reading column-oriented data into multi-dimensional variables, see Example 4 (in the DC_READ_FREE function description).
The format string is processed from left to right. Record terminators and format codes are processed until no variables are left in the variable list or until an error occurs. In a FORTRAN format string, when a slash record terminator ( / ) is encountered, the rest of the current input record is ignored, and the next input record is read.
TIP: If an error does occur, use the PRINT command to view the contents of the variables to see where the last successfully read value occurs. This will enable you to isolate the portion of the file in which the error occurred.
For more information about format reversion and group repeat specifications, see the PV-WAVE Programmer's Guide.
NOTE: The Nrecs keyword counts by logical records, if they have been defined. The Nskip keyword, on the other hand, counts by physical records, regardless of any logical record size that has been defined.
NOTE: By default, DC_READ_FIXED considers the physical record to be one line in the file, and the concept of a logical record is not needed. But if you are using logical records, the physical records in the file must all be the same length. The Bytes_Per_Rec keyword can be used only with column-oriented data files.
',' or '44'
NOTE: If you want to supply multi-character strings instead of individual characters, you can do this with the Ignore keyword. However, keep in mind that a character that matches Filters is simply discarded, and filtering resumes from that point, while a string that matches Ignore causes that entire line to be skipped.
If the end of the file is reached before all variables are filled with data, the remainder of each variable is set to Miss_Vals(0) if it was specified, or 0 (zero) if Miss_Vals was not specified. In this case, status is returned with a value less than zero to signify an unexpected end-of-file condition.
The dimensionality of the last variable in var_list can be unknown; a variable of length n is created, where n is the number of values remaining in the file. All other variables in var_list must be pre-dimensioned.
If you include the Resize keyword with the call to DC_READ_FIXED, the last variable can be redimensioned to match the actual number of values that were transferred to the variable during the read operation.
If you are interested in an illustration showing what row-oriented data can look like inside a file, see the PV-WAVE Programmer's Guide.
If a variable in var_list is undefined, a floating-point variable of length n is created, where n is the number of records read from the file. To get a similar effect in an existing variable, include the Resize keyword with the function call.
All variables specified with the Resize keyword are redimensioned to the same length
the length of the longest column of data in the file. The variables that correspond to the shortest columns in the file will have one or more values added to the end; either Miss_Vals(0) if it was specified, or 0 (zero) if Miss_Vals was not specified.If you are interested in an illustration demonstrating what column-oriented data can look like inside a file, see the PV-WAVE Programmer's Guide.
var1(50) and var2(2,50), one column of data will be transferred to var1 and two columns of data will be transferred to var2.
NOTE: If you want to intermingle multi-dimensional variables in var_list, you must be sure that the product of all dimensions (excluding the first dimension) of each variable is equal. For example, you can combine two-, three-, and four-dimensional variables in var_list if the variables have dimensions like these:
status=DC_READ_FIXED('results.wp', /Column, $
unit1, unit2, unit3, run_total, Ignore= $
["Total", "------", "$TEXT_IN_NUMERIC", $
"$BLANK_LINES"], Format="(F7.2,5X)")
results.wp and places the data into four variables: unit1, unit2, unit3, and run_total. Because the variables were not predefined, all data is interpreted as single-precision floating-point data, and all variables are treated as resizable one-dimensional arrays. Any blank lines or strings specified with the Ignore keyword (in this example, "
Total" and "------") are ignored. Also, any line with non-numeric characters in a numeric field is ignored.
status = DC_READ_FIXED('yields.doc', intake, $
chute, conveyor, crusher, /Column, $
Filter=['/', ':', ','], $
Format="(F7.2, 8X, F6.4, 3X)", $
Ignore=["$BLANK_LINES"])
yields.doc and places the data into four variables: intake, chute, conveyor, and crusher. Because the variables were not predefined, all data is interpreted as single-precision floating-point data, and all variables are treated as resizable one-dimensional arrays. Any extraneous characters (in this example, "/", ":", and ",") are discarded because the Filter keyword is provided. Also, all totally blank lines in the file are ignored.
simple.dat. The `.' characters in simple.dat represent blank spaces:
status = DC_READ_FIXED('simple.dat', var1, $
Format='(I4)', /Column)
var1=[1.0, 6.0, 11.0, 16.0]. Because var1 was not predefined, DC_READ_FIXED creates it as a one-dimensional floating-point array.On the other hand, the commands:
Var1 = INTARR(2)
Var2 = INTARR(2)
status = DC_READ_FIXED('simple.dat', var1, $
var2, Format='(2(4X, I4))', Nskip=2)
var1=[12, 14] and var2=[17, 19]. Because neither the Row or Column keyword was supplied, the file is assumed to use row organization.
nimrod.dat. The `.' characters in nimrod.dat represent blank spaces. nimrod.dat is very much like the data file in Example 3, except that it has a missing value where you would expect to see the numeral "8":
For example, the commands:
A = INTARR(20) & B = INTARR(20)
C = INTARR(20) & D = INTARR(20)
E = INTARR(20)
status = DC_READ_FIXED('nimrod.dat', $
A, B, C, D, E, Format='(2X, I2)', $
Resize=[1, 2, 3, 4, 5], /Column)
A=[1, 6, 11, 16], B=[2, 7, 12, 17], C=[3, 0, 13, 18], D=[4, 9, 14, 19], and E=[5, 10, 15, 20]. The missing value is interpreted as a zero (0). All variables are resized to a length of 4.On the other hand, the commands:
A = INTARR(20) & B = INTARR(20)
C = INTARR(20) & D = INTARR(20)
E = INTARR(20)
status = DC_READ_FIXED('nimrod.dat', $
A, B, C, D, E, Format='%d', $
Resize=[1, 2, 3, 4, 5], /Column)
A=[1, 6, 11, 16], B=[2, 7, 12, 17], C = [3, 9, 13, 18], D = [4, 10, 14, 19], and E = [5, 15, 20]. The missing value is skipped altogether, and E is resized to a length of 3 to reflect the number of values that were transferred into the variable. The other variables are resized to 4.Any variable that is not resizable (because it was omitted from the Resize vector), will be padded to the end with extra values. For the latter of the two calls to DC_READ_FIXED shown in this example, A, B, C, and D would be padded with an additional 16 zeroes, while E would be padded with an additional 17 zeroes. (Zeroes are used for the padding because Miss_Vals was not specified.)
If the file
nimrod.dat had used some other character as a delimiter, such as commas or slashes, both the C and FORTRAN format strings would have yielded the same result, namely, C = [3, 0, 13, 18]. It is only because of the way a C format skips over blank space that the C format was unable to detect the presence of a missing value.
status=DC_READ_FIXED(/Column, "xy5.dat", Xa, $
Ya, Format="(E9.3, 1X)", Bytes_Per_Rec=20)
Xa and Ya. Nor can the file be read as row-oriented data, because Xa would be filled completely before any data was transferred to Ya.
TIP: Only include the Bytes_Per_Rec keyword when you have a logical record that is longer or shorter than one line in the file. For the majority of column-oriented data files, one and only one value from each variable is on a single line, and the Bytes_Per_Rec keyword is completely unnecessary.
chrono.dat, that contains some data values and also some chronological information about when those data values were recorded:
01/01/92 10:30:35 10.00 04-30-92 32767 02/01/92 23:22:15 15.89 06-15-91 99999 05/15/91 03:03:03 14.22 12-25-92 87654
| Number | Template Description |
|---|---|
date1 = REPLICATE({!DT},3)
date2 = REPLICATE({!DT},3)
status = DC_READ_FIXED("chrono.dat", date1, $ date1, decibels,
Dt_Template=[1,-1], $
Format="(2(A8, 1X), F5.2)", /Column)
calib = INTARR(3)
status = DC_READ_FIXED("chrono.dat", date1, $
date1, decibels, date2, calib, /Column, $
Format="%8s %8s %f %8s %d", Ignore= $
["$BAD_DATE_TIME"], Dt_Template=[1,-1])
date1. Finally, since there is another date/time variable to be read (date2) and there are no more templates left, the template list is reset and Template 1 is used again. The template list is reset for each record.
NOTE: Because of the internal conversion that DC_READ_FIXED performs to convert the date strings to PV-WAVE's date/time internal structure, the date and time data must be read with theA8(FORTRAN) or%8s(C) format string.
wages.wp. All floating-point data in the file has been decimal-point-aligned by a word-processing application:
| 1070.00 | 9007.97 | 1100.00 | 1250.00 | 850.50 | 2010.00 |
| 5000.00 | 3050.00 | 1044.12 | 3500.00 | 6031.00 | 905.00 |
| 415.00 | 5200.00 | 1300.10 | 350.00 | 745.00 | 3000.00 |
| 200.00 | 3100.00 | 8100.00 | 7050.00 | 6780.00 | 2310.25 |
| 950.00 | 1050.00 | 1350.00 | 410.00 | 797.00 | 200.36 |
| 2600.00 | 2000.00 | 1500.00 | 2000.00 | 1000.00 | 400.00 |
| 1000.00 | 9000.00 | 1100.00 | 2091.00 | 3440.10 | 2000.37 |
| 5000.00 | 3000.00 | 1000.01 | 3500.00 | 6000.00 | 900.12 |
The following commands:
Maria = Fltarr(12) & Naomi = Fltarr(12)
Klaus = Fltarr(12) & Carlos = Fltarr(12)
status = DC_READ_FIXED('wages.wp', Maria, $
Carlos, Klaus, Naomi, Format="(F7.2,5X)", $
Ignore=["$BLANK_LINES"])
wages.wp and places the data into four variables: Maria, Carlos, Klaus, and Naomi. By default, row organization is assumed in the file, with five spaces separating the values in the file.With row organization, each variable is "filled up" before any data is transferred to the next variable in the variable list. This means that the first two lines of the file are transferred into the variable
Maria, the new two lines of the file are transferred into the variable Carlos, the next two lines of the file are transferred into the variable Klaus, and the last two lines of the file are transferred into the variable Naomi. The blank lines in the file are skipped entirely, preventing those lines from being interpreted as a series of zeroes.
For more information about fixed format I/O in PV-WAVE, see the PV-WAVE Programmer's Guide.

