 A string containing the pathname and filename of the file containing the data.
A string containing the pathname and filename of the file containing the data.
Readsfreely-formatted ASCII files.
A string containing the pathname and filename of the file containing the data.
The list of variables into which the data is read. Include as many variables names in var_list as you want to be filled with data, up to a maximum of 255. Note that variables of type structure are not supported. An exception to this is the !DT, or date/time, structure. It is possible to transfer date/time data using this routine.
The value returned by DC_READ_FREE; expected values are:
A flag that signifies filename is a column-organized file.Delim
An array of single-character strings that are the field separators used in the data file. If not provided, a comma- or space- delimited file is assumed.Dt_Template
An array of integers indicating the date/time templates that are to be used for interpreting date/time data. Positive numbers refer to date templates; negative numbers refer to time templates. For more details, see Example 5. To see a complete list of date/time templates, see the PV-WAVE Programmer's Guide.
Filters An array of one-character strings that PV-WAVE should check for and filter out as it reads the data. A character found on the keyboard can be typed; a special character not found on the keyboard is specified by ASCII code. For more details about the Filters keyword, see Filtering and Substitution While Reading Data.
Get_Columns
An array of integers indicating column numbers to read in the file. If not provided or if set equal to zero (0), all columns are read. Ignored if the Row keyword is supplied. An array of strings; if any of these strings are encountered, PV-WAVE skips the entire line and starts reading data from the next line. Any string is allowed, but the following three strings have special meanings:
Miss_Str
A string array that specifies strings that may be present in the data file to represent missing data. If not present, PV-WAVE does not check for missing data as it reads the file. An array of floating-point values, each of which corresponds to a string in Miss_Str. As PV-WAVE reads the input data file, occurrences of strings that match those in Miss_Str are replaced by the corresponding element of Miss_Vals. Number of records to read. If not provided or if set equal to zero (0), the entire file is read. For more information about records, see Physical Records vs. Logical Records.
Nskip
Number of physical records in the file to skip before data is read. If not provided or if set equal to zero (0), no records are skipped. An array of integers indicating the variables in var_list that can be resized based on the number of records detected in the input data file. Values in Resize should be in the range:
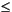 Resizen #_of_vars_in_var_list
Resizen #_of_vars_in_var_list
Row
A flag that signifies filename is a row-organized file. If neither Row nor Column is present, Row is the default. A long integer that specifies how many values comprise a single record in the input data file; use only with column-oriented files. If not provided, each line of data in the file is treated as a new record. For more details about when to use the Vals_Per_Rec keyword, see Example 4.
DC_READ_FREE relieves you of the task of composing a format string that describes the organization of the data in the input file. All you do is tell DC_READ_FREE which delimiters to expect in the file; comma and space are the default delimiters expected. In other words, DC_READ_FREE easily reads data values separated by any combination of commas and spaces, or any other delimiters that you explicitly define using the Delim keyword.
If neither the Row or Column keywords are provided, the file is assumed to be organized by rows. If both keywords are used, the Row keyword is assumed.
NOTE: This function can be used to read data into date/time structures, but not into any other kind of structures.
The string resource file is:
 wavedir
wavedir /xres/!Lang/kernel/dc.ads
/xres/!Lang/kernel/dc.ads wavedir:[XRES.!Lang.KERNEL]DC.ADS
wavedir\xres\!Lang\kernel\dc.ads
wavedir is the main PV-WAVE directory. The strings that are examined are
DC_binary_check and DC_allow_chars.
DC_binary_check This string can be set to the values True or False. If set to True, the data file is checked for the presence of binary characters before the file is read. If binary characters are found, the file is not read. If this string is set to False, no binary character checking is performed. (Default: True) For example, to turn off binary checking, set the string as follows in the
dc.ads file:
DC_binary_check: False
DC_allow_chars This string lets you specify additional characters to allow in the check for binary files. Before a file is read, the first several lines are checked for the presence of non-printable characters. If non-printable characters are found, the file is considered to be a binary file and the file is not read. By default, all printable characters in the system locale are allowed. Characters may be specified either by entering them directly or numerically by three digit decimal values by preceding them with a "\" (backslash). For example, to allow characters 165 and 220, set the string as follows in the
dc.ads file:
DC_allow_chars: \165\220
As data is being transferred into multi-dimensional variables, those variables are treated as collections of scalar variables, meaning the first subscript of the import variable varies the fastest. For two-dimensional import variables, this implies that the column index varies faster than the row index. In other words, data is transferred into a two-dimensional import variable one row at a time. For more details about reading column-oriented data into multi-dimensional variables, see Example 4.
If the current input line is empty or DC_READ_FREE has reached the end of the line and there are still unused variables in var_list, the next line is read. When there are no unused variables left in var_list, the remainder of the line is ignored.
NOTE: If the file contains string data, make sure the strings do not contain delimiter characters. Otherwise, the string will be interpreted as more than one string, and the data in the file will not match the variable list.
TIP: If an error does occur, use the PRINT command to view the contents of the variables to see where the last successfully read value occurs. This will enable you to isolate the portion of the file in which the error occurred.
NOTE: The Nrecs keyword counts by logical records, if they have been defined. The Nskip keyword, on the other hand, counts by physical records, regardless of any logical record size that has been defined.
NOTE: By default, DC_READ_FREE considers the physical record to be one line in the file, and the concept of a logical record is not needed. But if you are using logical records, the physical records in the file must all contain the same number of values. The Vals_Per_Rec keyword can be used only with column-oriented data files.
',' or '44'
TIP: Be sure not to filter characters that were used in the file as delimiters. The delimiters enable DC_READ_FREE to discern where one data value ends and another one begins.
NOTE: If you want to supply multi-character strings instead of individual characters, you can do this with the Ignore keyword. However, keep in mind that a character that matches Filters is simply discarded, and filtering resumes from that point, while a string that matches Ignore causes that entire line to be skipped.
If the end of the file is reached before all variables are filled with data, the remainder of each variable is set to Miss_Vals(0) if it was specified, or 0 (zero) if Miss_Vals was not specified. In this case, status is returned with a value less than zero to signify an unexpected end-of-file condition.
NOTE: Use a different delimiter to separate data values in the file than you use to separate the different fields of dates and times, such as months, days, hours, and minutes. Otherwise, your date/time data may not be interpreted correctly. The only delimiters that can be used inside date/time data are: slash ( / ), colon (:), hyphen (-), and comma (,).
When reading row-oriented data, only the dimensionality of the last variable in var_list can be unknown; a variable of length n is created, where n is the number of values remaining in the file. All other variables in var_list must be pre-dimensioned.
If you include the Resize keyword with the call to the function DC_READ_FREE, the last variable can be redimensioned to match the actual number of values that were transferred to the variable during the read operation.
If you are interested in an illustration showing what row-oriented data can look like inside a file, see the PV-WAVE Programmer's Guide.
If a variable in var_list is undefined, a floating-point variable of length n is created, where n is the number of records read from the file. To get a similar effect in an existing variable, include the Resize keyword with the function call.
All variables specified with the Resize keyword are redimensioned to the same length
the length of the longest column of data in the file. The variables that correspond to the shortest columns in the file will have one or more values added to the end; either Miss_Vals(0) if it was specified, or 0 (zero) if Miss_Vals was not specified.If you are interested in an illustration demonstrating what column-oriented data can look like inside a file, see the PV-WAVE Programmer's Guide.
For more information about how column-oriented data in a file is read into multi-dimensional variables, see Multi-dimensional Variables.
monotonic.dat:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
status = DC_READ_FREE('monotonic.dat', var1, $
/Column, Get_Columns=[3])
var1=[3.0, 8.0, 13.0, 18.0]. Because var1 was not predefined, DC_READ_FREE creates it as a resizable one-dimensional floating-point array.On the other hand, the commands:
var1 = INTARR(2)
var2 = INTARR(2)
status = DC_READ_FREE('monotonic.dat', var1, $
var2, /Column, Get_Columns=[2, 4], Nskip=2)
var1=[12, 17] and var2=[14, 19].
measure.dat:
0 5 10 15 20 25 30 35 40 45 50 56 61 66 71 76 81 86 91
96 101 107 112 117 122 127 132 137 142 147 152 158 163 168 173 178 183 188
193 198 203 209 214 219 224 229 234 239 244 249 255 255 255 255 255 255 255
255 255 255 255 255
var1 = INTARR(5)
var2 = INTARR(5)
status = DC_READ_FREE('measure.dat', $
var1, var2, Ignore=["$BLANK_LINES"])
var1 = [0, 5, 10, 15, 20] and var2 = [25, 30, 35, 40, 45]. Note that the file was interpreted as row-oriented data, since neither the Row or Column keyword was specified. All totally blank lines are ignored
NOTE: If the Resize = [2] keyword had been provided,var2would have been resizable and would have ended up having many more elements. Specifically,var2would have ended up with 57 elements instead of just 5.
intake.dat:
151-182-BADY-214-515 316-197-BADX-199-206
valve = INTARR(30)
status = DC_READ_FREE('intake.dat', $
valve, Miss_Str=["BADX","BADY"], $
Miss_Vals=[9999, -9999], Resize=[1], $
Delim=['-'])
valve=[151, 182, -9999, 214, 515, 316, 197, 9999, 199, 206]. The hyphens in the data are filtered out. Because valve is resizable, it ends up with 10 elements instead of 30. The two values from Miss_Vals are substituted for the two strings in the file, "BADX" and "BADY".
level.dat. This data file uses the semi-colon (;) and the slash (/) as delimiters, and the comma (,) to separate the thousands digit from the hundreds digit. This file has three logical records on every line; at the end of each logical record is a slash:
5,992;17,121/8,348;17,562/5,672;19,451/
5,459;18,659/7,088;17,052/8,541;13,437/
6,362;15,894/8,992;17,509/7,785;14,796/
gap = INTARR(20)
bar = INTARR(20)
status = DC_READ_FREE('level.dat', gap, bar, $
/Column, Delim=[';', '/'], Filter=[','], $
Resize=[1, 2], Vals_Per_Rec=2)
gap = [5992, 8348, 5672, 5459, 7088, 8541,6362, 8992, 7785]andbar = [17121, 17562,19451, 18659, 17052, 13437, 15894, 17509,14796].
Suppose you wanted
gap and bar to be dimensioned as 3-by-3 arrays instead of 1-by-9 vectors. The best way to do this is by reading the data with the commands shown above, and then using the REFORM command to redimension the variables:
gaparr = REFORM(gap, 3, 3) bararr = REFORM(bar, 3, 3)
For example, the following commands demonstrate the problem:
gap = INTARR(3, 3)
bar = INTARR(3, 3)
status = DC_READ_FREE('level.dat', gap, bar, $
/Column, Delim=[';', '/'], Filter=[','], $
Resize=[1, 2], Vals_Per_Rec=2)

gap using the rule, "The first subscript varies fastest." With Vals_Per_Rec set to "2", no value is available for the third columnhence, every element in the third column is set equal to "0" (zero). Furthermore, notice that gap gets all the data (it is resizable) and bar gets none of the data.
events.dat, that contains some data values and also some chronological information about when those data values were recorded:
01/01/92 5:45:12 10 01-01-92 3276 02/01/92 10:10:10 15.89 06-15-91 99 05/15/91 2:02:02 14.2 12-25-92 876
| Number | Template Description |
|---|---|
| 1 | MM*DD*YY (* = any delimiter) |
| -1 | HH*MM*SS (* = any delimiter) |
date1 = REPLICATE({!DT},3)
status = DC_READ_FREE("events.dat", date1, $
date1, float1, /Column, $
Dt_Template=[1,-1], Delim=[' '])
FOR I = 0,2 DO BEGIN
PRINT, date1(I), float1(I)
ENDFOR
{ 1992 01 01 05 45 12.00 87402.240 0}
10.0000 { 1992 02 01 10 10 10.00 87433.424
0} 15.8900 { 1992 05 15 02 02 02.00
87537.035 0} 14.2000
date1 is a structure, curly braces, "{" and "}", are placed around the output. When displaying the value of date1 and float1, PV-WAVE uses default formats for formatting the values, and attempts to place as many items as possible onto each line.
TIP: Another alternative to view the contents ofdate1andfloat1is to use the DT_PRINT command instead of PRINT.
To read the first, second, fourth, and fifth columns, define an integer array and another date/time variable, and change the call to DC_READ_FREE as shown below:
calib = INTARR(3)
date2 = REPLICATE({!DT},3)
status = DC_READ_FREE("events.dat", date1, $
date1, date2, calib, /Column, Delim=[' '], $
Get_Columns= [1, 2, 4, 5], Dt_Template = $
[1, -1], Ignore=["$BAD_DATE_TIME"])
date1. Finally, since there is another date/time variable to be read (date2) and there are no more templates left, the template list is reset and Template 1 is used again. The template list is reset for each record.
NOTE: Because of the internal conversion that DC_READ_FIXED performs to convert the date strings to PV-WAVE's date/time internal structure, the date and time data must be read with theA8(FORTRAN) or%8s(C) format string.
See the PV-WAVE Programmer's Guide for more information about free format I/O in PV-WAVE.

